

FastAdmin框架
add/edit 字段条件判断
$params = $this->request->post(‘row/a’);
新增功能 controtroller + mdoel + validate+view + public/assets/js +菜单规则
解决跨域问题
// check_cors_request();
header('Access-Control-Allow-Origin: *');
header('Access-Control-Allow-Methods: POST, GET, PUT, OPTIONS, DELETE'); //请求方法
header('Access-Control-Allow-Headers: Origin, X-Requested-With, Control-Type, Content-Type, token, Accept, x-access-sign, x-access-time');
if (request()->isOptions()) {
exit();
}
Redis简介
一、简单介绍
1、string字符串类型
String是Redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M

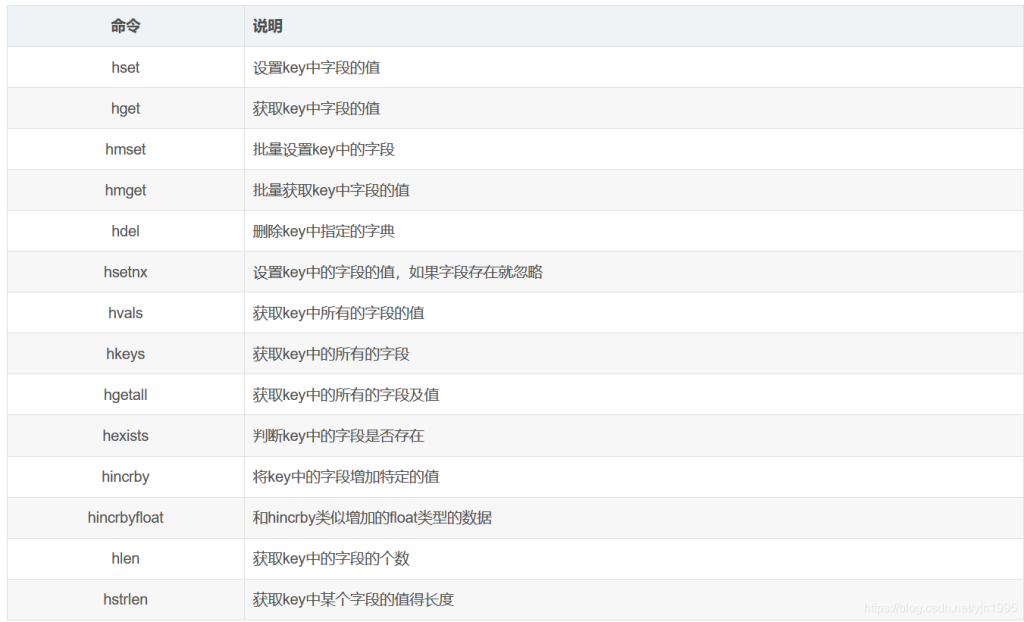
2、hash哈希类型
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。类似Java里面的Map
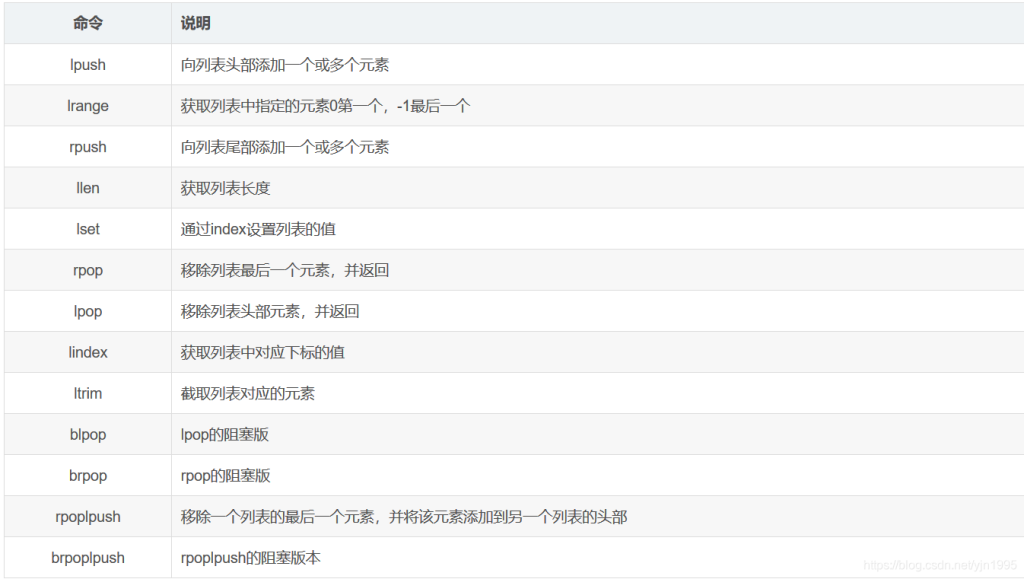
3、list列表类型
单键多值
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
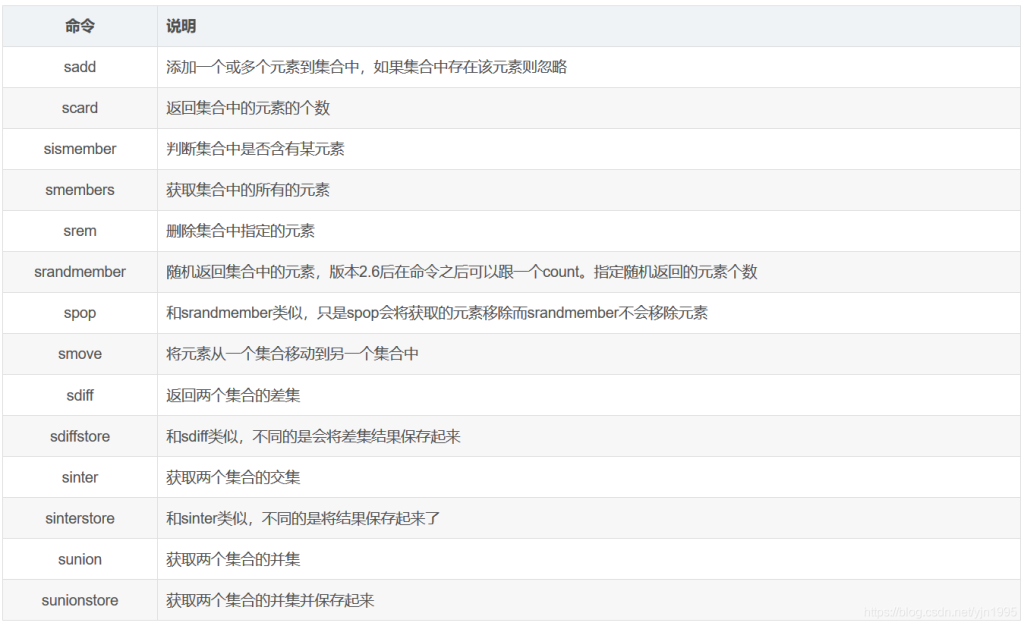
4、set集合类型
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变
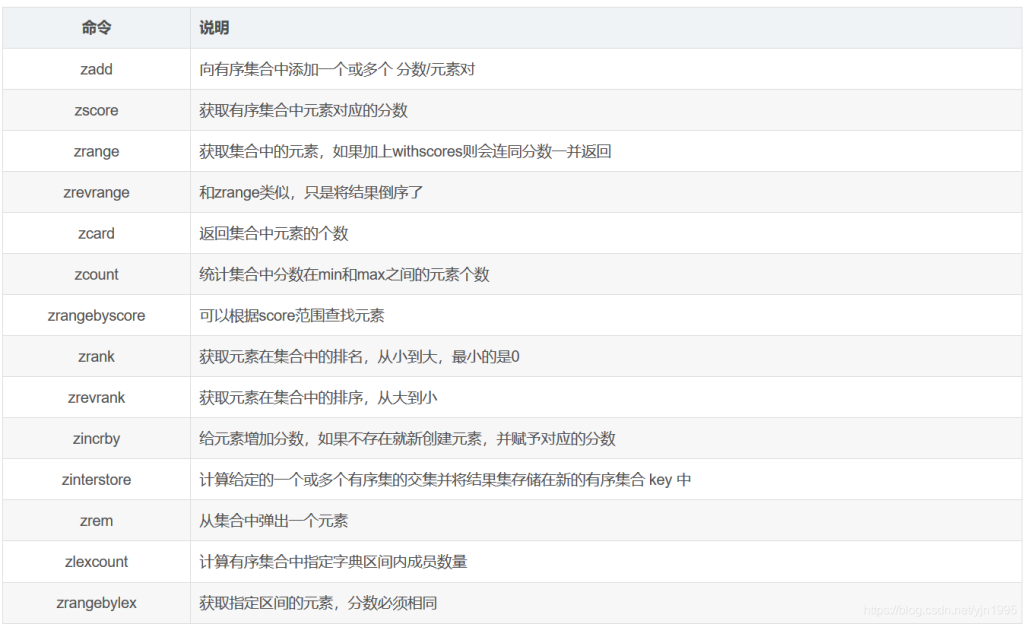
5.zset有序集合类型
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
示例
1.计数器 string
单线程,避免并发问题,保证不会出错,毫秒级性能
命令:INCRBY incrby
2.队列 list 简单消息队列、用户第几个访问、新闻列表排序
由于redis把数据添加到队列是返回添加元素在队列的第几位,所以可以做判断用户是第几个访问这种业务
新闻列表页面最新的新闻列表,redis的 LPUSH命令构建List
3.在线状态、签到(大数据处理)
几亿用户系统的签到,去重登录次数统计,用户是否在线状态
setbit、getbit、bitcount命令
原理是:
redis内构建一个足够长的数组,每个数组元素只能是0和1两个值
数组的下标index用来表示我们上面例子里面的用户id
4.hash实现幂等性请求
(hash实现幂等性请求)验证前端的重复请求,通过redis进行过滤:每次请求将request ip、参数、接口等hash作为key存储redis,设置多长时间有效期,然后下次请求过来的时候先在redis中检索有没有这个key,进而验证是不是一定时间内过来的重复提交
5.秒杀系统(防止超卖),单线程特征,自增,无并发问题 string
6.全局增量ID生成 生成全局唯一商品序列号、插入数据重复问题
7.排行榜 zrevrank 查看前n名 ZRANGE 查看所有排名 O(log(N))
Mysql语句
一.索引
1)单列索引
普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
唯一索引:索引列中的值必须是唯一的,但是允许为空值。
主键索引:是一种特殊的唯一索引,不允许有空值。
2)组合索引
在表中的多个字段组合上创建的索引
组合索引的使用,需要遵循最左前缀原则(最左匹配原则,后面高级篇讲解)。
一般情况下,建议使用组合索引代替单列索引(主键索引除外,具体原因后面知识点讲解)。
3)全文索引
只有在MyISAM引擎上才能使用,而且只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引。
4)空间索引
不做介绍,一般使用不到。
二.高级查询
子查询(嵌套查询)
一个 select 语句中,嵌入另外一个 select 语句, 被嵌入的 select 语句称为子查询语句,外部select语句则称为主查询。 主查询和子查询的关系 子查询是嵌入到主查询中 子查询是辅助主查询的,要么充当条件,要么充当数据源 子查询是可以独立存在的语句,是一条完整的 select 语句
语法:语法:嵌套查询也就是在查询语句中包含有子查询语句,所以叫嵌套查询,没有单独的语法,嵌套子查询通常位于查询语句的条件之后;
-- 先查询学生平均年龄,再查询大于平均年龄的学生
select * from student where age > (select avg(age) from student);连接查询
MySQL查询连接主要分为三类:内连接、外连接和交叉连接。
内连接
INNER JOIN
-- 内连接
语法:select 字段 from 表1 inner join 表2 on 表1.字段 = 表2.字段;
根据两个表中共有的字段进行匹配,然后将符合条件的合集进行拼接
on后面是连接条件,也就是共有字段
select * from student inner join engScore on student.name = engScore.name;
-- 将 student 表与 engScore 表通过相同的 name 拼接起来,简单的来说就是两个 excel 合并外连接
OUTER JOIN
对于外联结 outer关键字可以省略
外连接分为左连接和右连接,这种连接是指在连接两张或多张表时,包含了所有的记录。
左(外)连接
-- 左连接
语法:select 字段 from 表1 left join 表2 on 连接条件;
select * from student left join engScore on student.name = engScore.name;
-- 与内连接形式相同,但左表为主表,指定字段都会显示,右表为从表,无内容会显示 null右(外)连接
-- 右连接
语法:select 字段 from 表1 right join 表2 on 连接条件;
select * from student right join engScore on student.name = engScore.name;
-- 与内连接形式相同,但右表为主表,指定字段都会显示,左表为从表,无内容会显示 null三.主从复制
1 )在 slave 服务器上执行 start slave 命令,主从复制开始进行
2)此时,slave 服务器的 I/O 线程 会通过在 Master 上已经授权的用户请求连接 Master 服务器 ,并请求从指定 binlog 日志文件的指定位置(日志文件名和位置就是在配置主从复制服务时执行 change master 命令指定的)之后开始发送 binlog 日志内容
3) Master 服务器接收到来自 slave 服务器的 I/O 线程的请求之后,其上负责复制的 binlog dump 线程会根据请求的信息,分批读取指定 binlog 日志文件所指定位置之后的 binlog 日志信息,然后返回给 Slave 端的 I/O 线程。 返回的信息中除了 binlog 日志内容之外,还包括在 Master 服务器端记录的新的 binlog 文件名称, 以及在新的 binlog 中的下一个指定的更新位置
4)当 slave 服务器的 I/O 线程获取到 Master 服务器上 I/O 线程发送的日志内容及 日志文件和位置点之后 ,会将 binlog 日志内容依次写入到 Slave 端自身的 Relay Log (即中继日志)文件( MySQL-relay-bin.xxxxxx )的最末端,并将新的 binlog 文件名和位置记录到 master info 文件中,以便下次读取 Master 端新 binlog 日志时,能够告诉 Master 服务器需要从新 binlog 日志的指定文件及位置开始请求新的 binlog 日志内容
5 ) Slave 服务器端的 SQL 线程会实时地检测本地 Relay Log 中 I/O 线程新增加的日志内容,然后及时地把 Relay Log 文件中的内容解析成 SQL 语句, 并在自身 slave 服务器上按解析 SQL 语句的位置顺序执行,并将当前应用中继日志的文件名及位置点记录在 relay- log.info
PHP Array
一.交集和差集
1.交集
(1).array_intersect()函数返回一个保留了键的数组,这个数组只由第一个数组中出现的且在其他每个输入数组中都出现的值组成
(2).函数array_intersect_assoc()与array_intersect()基本相同,只不过他在比较中还考虑了数组的键。因此,只有在第一个数组中出现,且在所有其他输入数组中也出现的键/值对才返回到结果数组中。
(3)函数array_intersect_key()函数使用键名比较计算数组的交集
2.差集
(1).函数array_intersect_key()函数使用键名比较计算数组的交集
(2).array_intersect_assoc() 函数用于比较两个(或更多个)数组的键名和键值,并返回一个交集数组,这个数
组只由第一个数组中出现的且在其他每个输入数组中都出现的键名和键值组成。
二.常用函数
1.is_array()函数:
is_array()函数的作用是判断一个变量是否是数组,如果是数组,则返回true,否则返回false。
2.array_unique()函数
array_unique()函数的作用是移除数组中的重复元素。
3.array_search()函数:
在数组array中搜索某个键值value,并且返回对应的键名
array_push():
向第一个参数的末尾添加一个或多个元素(入栈),然后返回新的数组长度
array_pop():
删除数组中的最后一个元素
使用格式:array_pop(array)
array_shift():
删除数组中的第一个元素,并返回被删除元素的值
使用格式:array_shift(array)
array_unshift():
像数组插入新元素,新数组的值将会被插入到数组的开头
1.array_change_key_case($arr,CASE_UPPER/CASE_LOWER)将$arr的键值转换为大写或者小写
2.array_combine($arr1, $arr2) $arr1的值作为键,$arr2作为值生成后返回新的数组
3.array_key_exists(‘key’, $arr)$arr中是否存在key,如果存在返回true,如果不存在返回false
4.array_keys($arr)以数组形式返回$arr中所有的key值
5.array_values($arr)以数组形式返回$arr中所有的values的值
6.count($arr, $mode=COUNT_NORMAL)计算数组的个数
7.array_count_values($arr)计算数组的中的值出现次数,形成新的数组,key为原数组的值,value为出现的次数
8.sort($arr,$mode)重要的排序数组函数
$mode模式为:
①SORT_REGULAR,0,默认项,常规排序,按照ASCII排序,不改变类型。
②SORT_NEMERIC,1,把每一项作为数字来处理
③SORT_STRING,2,把每一项作为字符串来处理
④SORT_LOCALE_STRING,3,把每一项作为字符串来处理,基于当前区域设置(可通过setlocale()进行更改)
⑤SORT_NATURAL,4,把每一项作为字符串来处理,使用类似natsort()的自然排序
⑥SORT_FLAG_CASE,5,可以结合(按位或)SORT_STRING或SORT_NATURAL对字符串进行排序,不区分大小写
9.ksort($arr,$sort_flags)将数组按照键名升序排列,对应的krsort()按照键名降序排列
10.asort($arr,$sort_flags)将数组按照值升序排列,asort()将数组按照值降序排列
11.shuffle()随机打乱数组中的元素会生成新的key
12.array_flip($arr)将数组的键与值进行交换,生成新的数组并返回
13.array_unique($arr)将数组的中重复的值删去,生成新的数组并返回
14.array_pop($arr)删除数组的最后一个元素,返回删除的元素的值,对应的array_push(array &$array, $var, $_ =null)在数组$array末尾插入$var的值也可以插入多个值,返回为$array新的个数.
15.array_shift($arr)删除数组的第一个元素,返回删除的元素的值,对应的array_unshift(array &$array,$var,$_= null)在数组$array开头插入$var的值也可以插入多个值,返回为$array新的个数.
16.array_sum($arr)计算数组中的所有值的和并返回,确保数组中的值都为数字
17.compact($varname, $_=null)重要连接变量返回数组的函数,key为变量名,value对应的是$varname的值.
18.extract($arr,$extract_type =null,$pre_fix=null),方便的将数组中的每个元素创建成相应的变量,变量名为key(如果设定了$pre_fix会加入前缀),value对应的是变量的值.
19.in_array($needle, array $haystack, $strict = null)查找在$haystack中是否存在与$needle值相等的元素(==)如果strict为true,则开启严格查找模式,会比较类型.
20.array_rand(array $input,$num_req=null) 在$input数组当中随机抽取$num_req个元素,返回数组由key组成(不包含value)或者是一个key.
21.array_merge($array1,$array2)将两个数组合并,规则索引下标会自动重新分配下标,关联下标会用后面的值覆盖前面的值.
22.unset($arr[‘key’])删除数组中的指定元素
23.serialize($arr)序列化数组返回字符串,unserialize($str)反序列化字符串转换成数组,目的利于数组保存到文件数据库当中去.
24.array_slice($array, $offset,$length,$preserve_keys=null)从array的$offset位置开始截取$length个元素,返回截取的数组.
25.array_splice(array &$input, $offset,$length=null,$replacement = null)将input数组的$offset位置开始截取$length个元素,$replacement插入这个位置,$input被改变,返回被替换的数组.
git命令
git init 初始化
git add . 添加 所有内容 到缓存区
git commit -m ‘first commit’ 提交注释
git remote add origin git@github.com:帐号名/仓库名.git 添加远程git库地址
git pull origin master 拉取主分支内容
git push origin master # -f 强推
git clone git@github.com:git帐号名/仓库名.git 克隆远程git库
拉取 某次提交内容 到 当前分支
git cherry-pick <commitHash>
将 feature 分支的最近一次提交,转移到当前分支
git cherry-pick feature
将 A 和 B 两个提交应用到当前分支
git cherry-pick <HashA> <HashB>
可以转移从 A 到 B 的所有提交 提交 A 必须早于提交 B,否则命令将失败,但不会报错。注意,使用上面的命令,提交 A 将不会包含在 Cherry pick 中
git cherry-pick A..B
如果要包含提交 A,可以使用下面的语法。
git cherry-pick A^..B
git checkout master 切到主分支
git fetch origin 获取最新变更
git checkout -b dev origin/master 基于主分支创建dev分支
git add . 添加到缓存
git commit -m ‘xxx’ 提交到本地仓库
git fetch origin 获取最新变更
git status
git add 文件名 将工作区的某个文件添加到暂存区
git add . 将当前工作区的所有文件都加入暂存区
git add -u 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件
git add -A 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件
git add -i 进入交互界面模式,按需添加文件到缓存区
git commit -m “提交说明” 将暂存区内容提交到本地仓库
git commit -a -m “提交说明” 跳过缓存区操作,直接把工作区内容提交到本地仓库
6、查看历史记录
git log 查看所有commit记录(SHA-A校验和,作者名称,邮箱,提交时间,提交说明)
git log -p -次数 查看最近多少次的提交记录
git log --stat 简略显示每次提交的内容更改
git log --name-only 仅显示已修改的文件清单
git log --name-status 显示新增,修改,删除的文件清单
git log --oneline 让提交记录以精简的一行输出
git log --graph --all --online 图形展示分支的合并历史
git log --author=作者 查询作者的提交记录(和grep同时使用要加一个--all--match参数)
git log --grep=过滤信息 列出提交信息中包含过滤信息的提交记录
git log -S查询内容 和--grep类似,S和查询内容间没有空格
git log fileName 查看某文件的修改记录
git reset HEAD^ 恢复成上次提交的版本
git reset HEAD^^ 恢复成上上次提交的版本,就是多个^,以此类推或用~次数
git reflog
git reset --hard 版本号
--soft:只是改变HEAD指针指向,缓存区和工作区不变;
--mixed:修改HEAD指针指向,暂存区内容丢失,工作区不变;
--hard:修改HEAD指针指向,暂存区内容丢失,工作区恢复以前状态;
查看分支:git branch -a
合并分支:
git merge dev #用于合并指定分支到当前分支
git merge --no-ff -m “merge with no-ff” dev #加上--no-ff参数就可以用普通模式合并,合并后的历史有分支,能看出来曾经做过合并
git相关配置
git config --global user.name “用户名” # 设置用户名
git config --global user.email “用户邮箱” #设置邮箱
git config --global user.name # 查看用户名是否配置成功
git config --global user.email # 查看邮箱是否配置
git config --global --list # 查看全局设置相关参数列表
git config --local --list # 查看本地设置相关参数列表
git config --system --list # 查看系统配置参数列表
git config --list # 查看所有Git的配置(全局+本地+系统)
git config --global color.ui true //显示git相关颜色
撤消某次提交
git revert HEAD # 撤销最近的一个提交
git revert 版本号 # 撤销某次commit